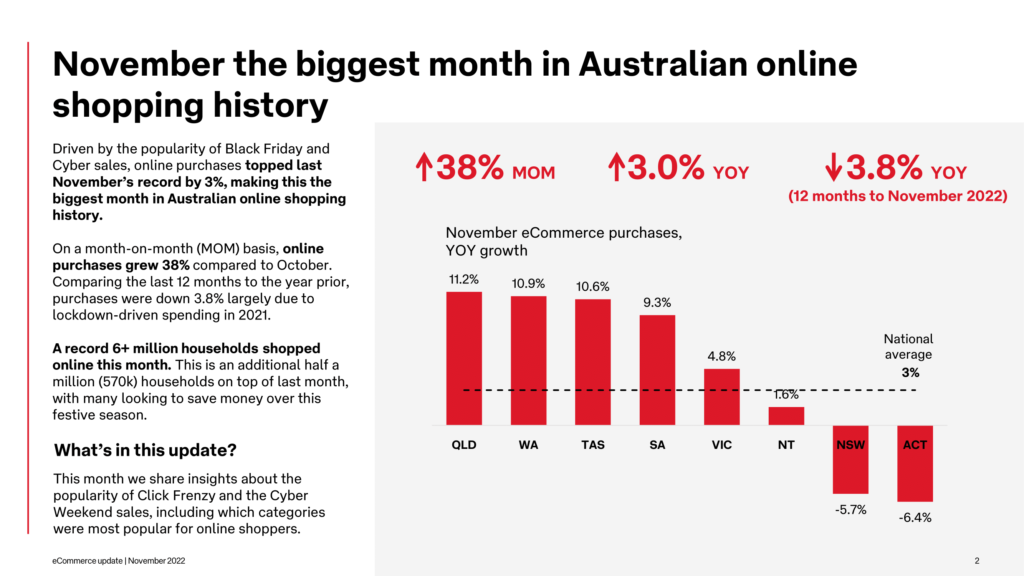
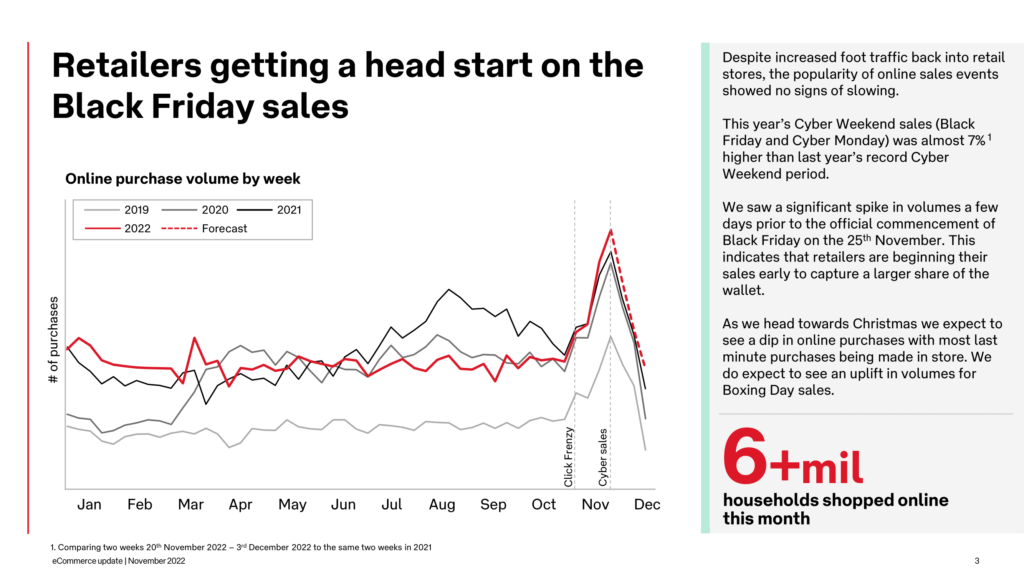
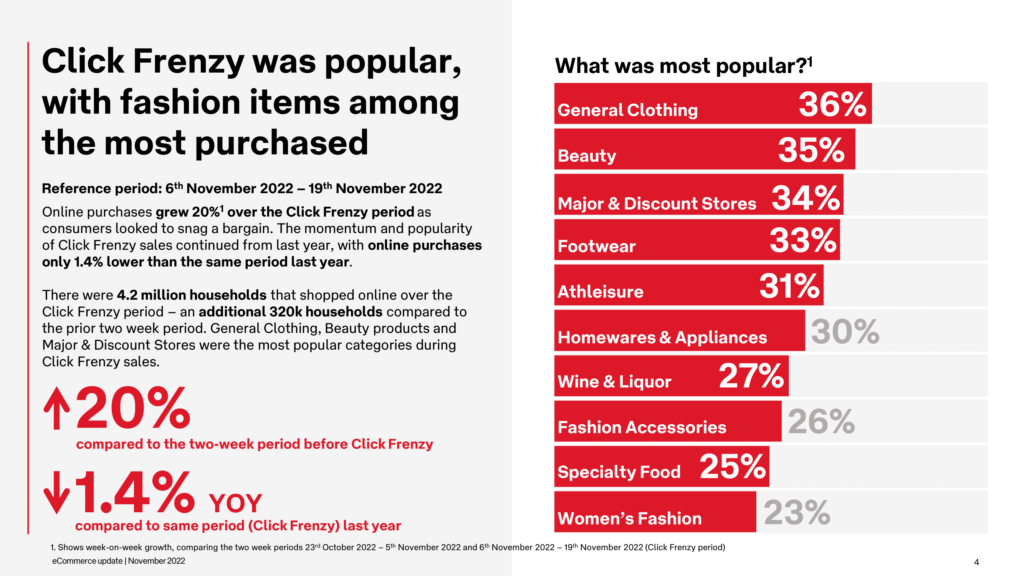
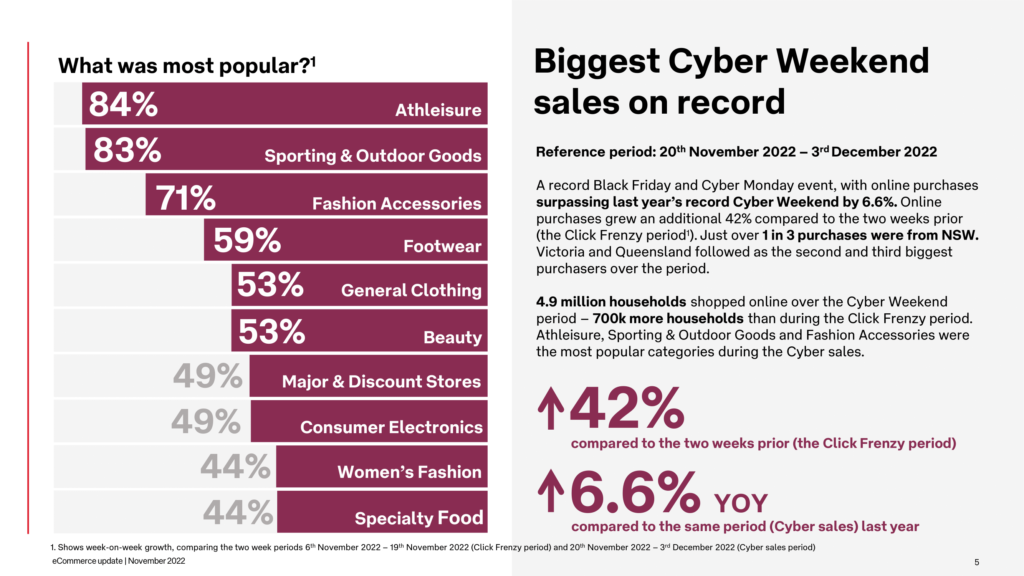
At first glance, the Playing Field hasn’t changed much since the world started leveraging eCommerce and retail technologies. The eCommerce ecosystem is now moving towards sophistication that was once inaccessible for many retailers and reasons Chief Technology Officer of eStar Matt Neale outlines. The infrastructure has upgraded, becoming highly dynamic, reacting to customer and competitor behaviour in live mode, targeting views and offers to provide maximum value.
In this article, we will cover the online shopping trends that will shape the eCommerce industry in 2023 and sometimes even further future of online businesses, including but limited to the technical aspects.
Online Shopping Market Landscape Trends
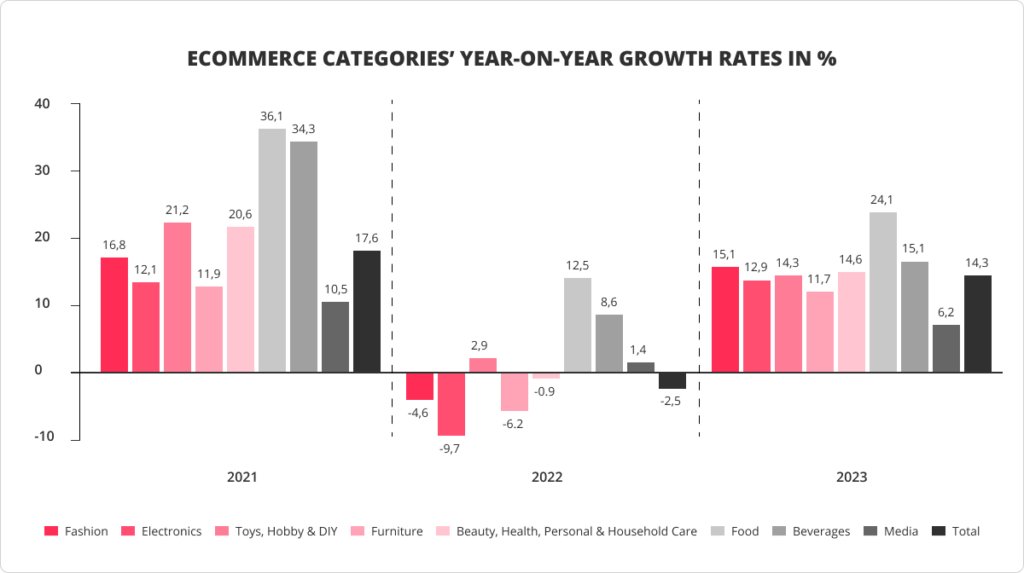
In 2022 global retail market experienced the tendency to return to offline sales after the pandemic, which slowed down the eCommerce increase pace. Nevertheless, the eCommerce revenue growth is forecasted to bounce back in 2023 and grow until 2025.
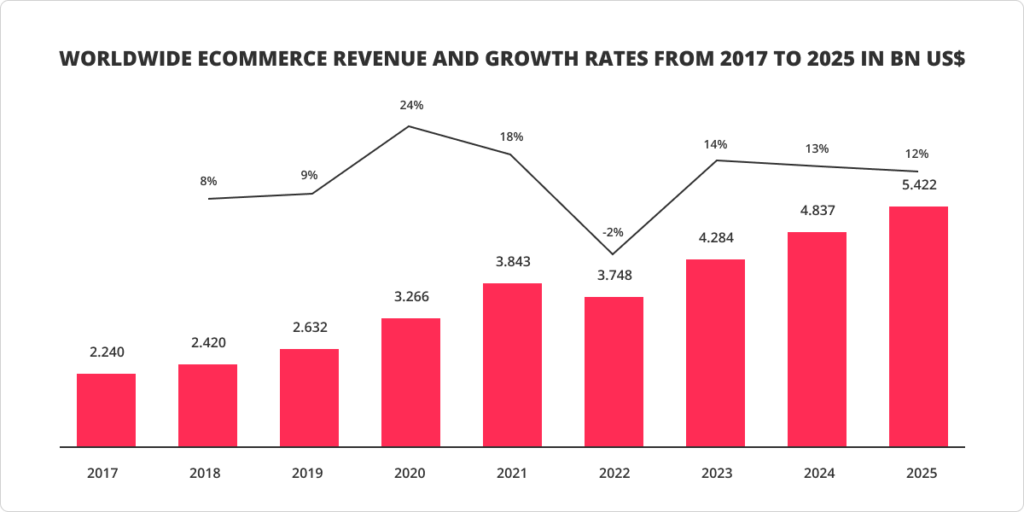
While in the past year, only essential needs like Food & Beverages were performing well, this year, the growth rate for all major eCommerce categories will increase, and several of them can even outperform the 2021 indicators.
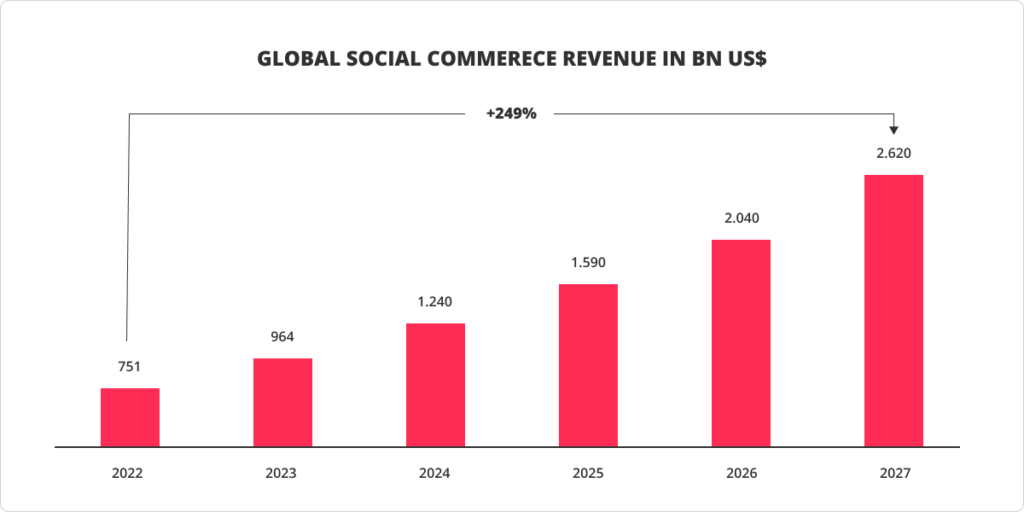
Social media as an eCommerce trend
The time when marketing practitioners pouring budgets on social media was asked, “Does Social Media Sell?” had passed. 94% of all internet users worldwide nowadays are also social media users, and it directly affects the development of eCommerce. The significance of social media, which is from being barely one of the communication channels boosted towards being an essential sales tool, is unnegotiable, and it expresses in the generated revenue increasing exponentially yearly.
Preference prediction in the eCommerce industry
Intimate human experience, help with browsing, personalised advice and product recommendations are the points where traditional retail still has advantages in front of eCommerce. Online shopping trends incline eCommerce retail businesses to imitate face-to-face shopping assistance further by attentively tracking customer preferences and behaviour, retrieving deepened insights and optimising the shopping process by applying intelligent solutions. As a result, the “recommended products” block on the websites and other similar features are expected to become even more advanced.
Voice search impact on eCommerce
The way people search for services and products is also evolving. Data suggests that by 2024 over 8.4 billion digital voice assistants will be used worldwide. Consumer query that was typed focuses on specific keywords, whereas voice search is more likely to happen in the form of a question. For instance, “black shoes” vs. “Where can I buy black shoes?” Considering significant differences between typed-in and voice search, eCommerce business owners should observe this online shopping trend closely since it might seriously change the best practices of organic and paid search engine marketing channels.
Cryptocurrency for e-business growth
When integrating cryptocurrency into the business, the owners’ main anxiety was the lack of understanding of the crypto concept among the consumers. However, the studies demonstrated solid proof for the inconsistency of this doubt: 43% per cent of respondents claim their understanding of the concept, 35% consider it as a legitimate form of currency, and 28% view it as the future of currency. Moreover, surveys have shown that over 1 in 5 Gen Z, Millennial, or Gen X respondents invest in crypto, whereas 34% of crypto owners already have used it to make purchases other than buying crypto.
Thus, it could become one of the main tendencies that shape the future of eCommerce and brands that integrate cryptocurrency features into their eCommerce platforms can facilitate faster payments with an expansive multinational customer reach.
Chatbots in conversational marketing development in eCommerce
In real-time one-on-one interactions in their preferred channel, lay opportunities to build close personal relationships with customers and provide more value to their experience with the company. Additionally, conversational marketing helps gather more data and information from your customers, neatly nudges customers further along the funnel and enriches the customer experience by feeling more connected to the organisation.
Customisable conversational marketing interactions can be tailored to the customer’s needs and, therefore, could replace long lead forms and complement each touchpoint at every stage of the customer journey. However, keeping up with the “always-online” customer is not feasible for most businesses. If their questions are simple or they don’t want to wait for a human, most consumers who ask for a live chat while shopping online are happy to interact with chatbots as long as they know indeed that it is a chatbot. Recent generation live chats allow brands to keep interactions coherent with their brand voice. Moreover, the recent tendencies in AI-guided chatbots like ChatGPT and related competition will further warm the conversational marketing trend in eCommerce.
Virtual reality and metaverse trends that will affect the future of marketing
A new level of brands’ interaction with consumers develops towards a virtual environment known as “the metaverse”. 40% of respondents already claim that they understand the metaverse concept. Among the over 80% of those who reported shopping across at least three channels over the last six months, one out of three say they used a virtual reality (VR) channel, and a significant number of them used it to buy retail products and luxury goods.
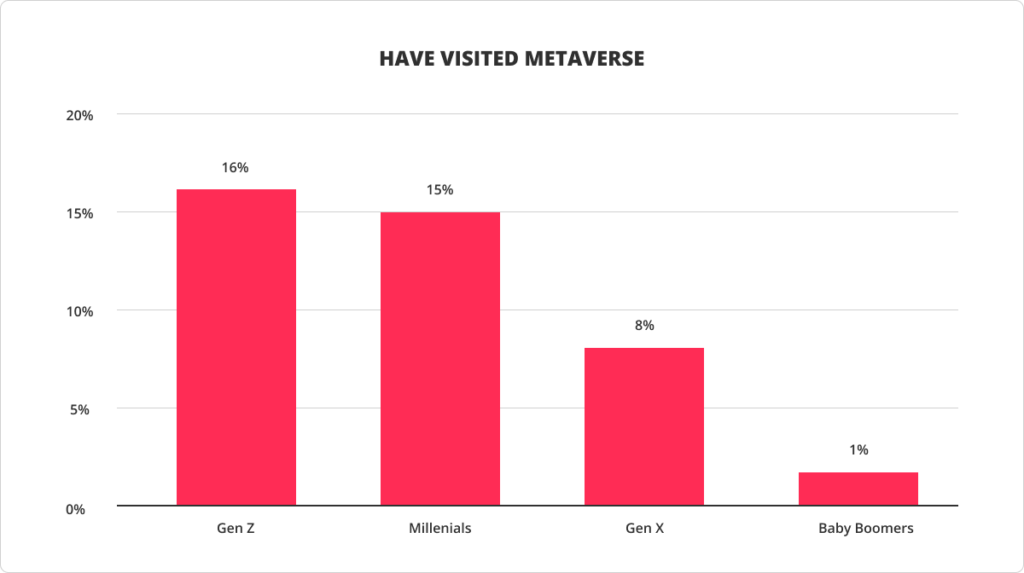
Metaverses are built as the elements of the web3 concept. As one of the ways for brands to improve customer engagement, virtual stores in the metaverse let retailers provide their customers with an immersive experience, already promising to become a game-changer in the future of online business. Although there are still open questions, the milestones of consumer interaction, as for the entire eCommerce now, will still be the smooth transition and seamless connection. Whereas interconnected and trustworthy omnichannel brand experience importance will only increase.
Redefined retail experience for the future of online businesses
Although the scope of tools hasn’t changed much since the world started leveraging eCommerce and retail technologies, being a specialist eCommerce marketing agency, LION Digital closely observes a new way of people’s thinking about e-shopping. We understand the constant need for redefinition and choose to partner with companies that strive to upgrade online retail for the healthy future development of eCommerce.
eStar is a proven, only enterprise-level total eCommerce solutions platform that works directly with brands and businesses to deliver ongoing growth. eStar’s mission is: “Empower client success by redefining the retail experience”. Client portfolio includes companies like David Jones, Country Road Group, Briscoe Group, Air New Zealand, Bed Bath & Beyond, Stirling Sports and many more.
To achieve outstanding outcomes eStar has a passion for working collaboratively with clients, thus, is a perfect partner:
- For CEOs and owners who are concerned and frustrated by the lack of sales and online growth
- For Digital Executives and Marketing who are struggling with low conversion rates
- For Successful in the past retailers who are now experiencing anxiety due to stagnant and lacklustre results.
GET IN CONTACT TODAY AND LET OUR TEAM OF ECOMMERCE SPECIALISTS SET YOU ON THE ROAD TO ACHIEVING ELITE DIGITAL EXPERIENCES AND GROWTH
Contact Us

Article by