


As many new businesses have transitioned online and started to invest in digital strategies in the last two years, this has created a supply and demand dilemma with the algorithms in paid media.
CPC costs have risen by 150% or more compared to previous years and this trend doesn’t seem to be softening in a hurry
I’m sure you’ve experienced the pinch of this trend if your topline revenue relies heavily on paid advertising.
While LION is across 100s of data points and we keep a close eye on our client’s ad spend to make sure we’re squeezing the most revenue possible from this channel, one thing is for sure.
THE ECOMMERCE GAME IS CHANGING IN 2022
The email channel has always been a fairly misunderstood part of eCommerce from my experience. Most of the brands I start working with only have checkout abandonment automations and a welcome series turned on, and run 1-2 campaigns per week. There is so much more that can be done with this channel to enhance the customer journey or grow the database,
and the Klaviyo platform is the only way to do it!
The real power of the email channel is twofold. You own the experience that you create for your customers (aka you are in control), and, you can target highly specific communication to your loyal customers at pivotal points in their customer journey (read: help them take meaningful actions to your brand). Klaviyo gives you the control you need to do both.

Nutrition Warehouse
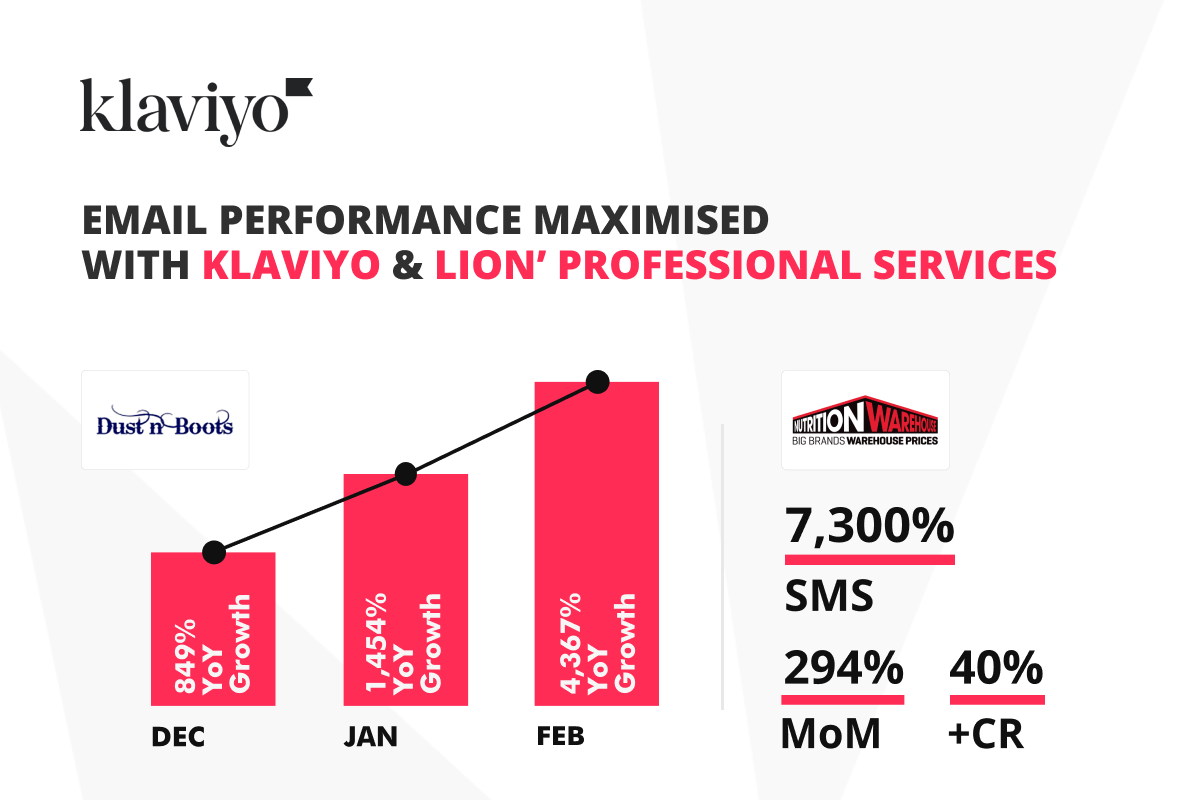
Nutrition Warehouse, one of the largest supplement brands in the country that we started working with, in mid-January, has seen incredible growth in a short period of time.
294% MoM growth, a 40% increase in conversions from the email, 7,300% growth in their SMS channel, and March to date have seen the trend continue with 99% growth from the previous month, and an average transaction value of $9 higher than the site average. A large contributor to this growth has been the X45 email and SMS campaigns that were sent last month, using Klaviyo’s sophisticated segmentation tools.

294%
40%
7,300%
99%
+9$
Shoe Me
Shoe Me, a specialty shoe store that we work with has seen 15% growth in February from January which was already up 56% from the previous month in December. Historically, at the start of the year, sales are down, however, sending a much higher quantity of campaigns than they did previously to highly segmented audiences has generated these returns. We moved from 11 campaigns per month in December, to 19 in January and February.

11
19
Increase in campaigns from Dec 21 to Feb 22, allowed for MoM growth in a usually down sales period.
DUST N BOOTS
We started with an apparel brand that sells country workwear in July last year, Dust N Boots. They had zero email program and now in February this year it accounted for 34% of their total revenue, and this has not cannibalised revenue from other channels.


GET IN CONTACT TODAY AND LET OUR TEAM OF ECOMMERCE SPECIALISTS SET YOU ON THE ROAD TO ACHIEVING ELITE DIGITAL EXPERIENCES AND GROWTH
Contact Us

Leonidas Comino – Founder & CEO
Leo is a, Deloitte award winning and Forbes published digital business builder with over a decade of success in the industry working with market-leading brands.
Like what we do? Come work with us

